Overfitting refers to the modeling error that occurs when an AI model functions excessively on specific data. Though it performs well on such training data but fails on new, unlabeled data, it remains a noteworthy challenge. Businesses can overcome this challenge by focusing on diverse training datasets and developing artificial intelligence systems that are both reliable and scalable.
This content piece delves deep into the importance of data diversity and effective approaches to achieving it and preventing overfitting, particularly in the model training process used by data annotation companies.
Overfitting: AI’s Perfectionist Problem!
In the context of a student, overfitting is like a student who only studies the exact questions from the previous year's test and does not focus on the subject. They might not know how to answer if the test changes even a little.
For an AI model, overfitting means it gets really good at remembering the examples it was trained on but struggles with anything new. It's like learning that all dogs in pictures must have grass because image annotations showed dogs in parks. Then, when shown an image of a dog in a living room, the model gets confused.
To stop this from happening, model training should focus on a few important aspects, such as data diversity, quality annotations, metadata, etc., in recognizing the dog itself, not just where it’s sitting. This way, it can function well with any image, even new ones that haven’t been seen before in the model training process.
Why Data Diversity is Important in AI Model Training?
We know that overfitting occurs when the model is trained on one data point and not on diverse data. In this regard, data heterogeneity captures a comprehensive understanding of its target domain, minimizing the risk of overfitting. This inclusion of a wide range of variations prevents overfitting.
These variations may include:
Domain-specific Diversity: AI robot models are now trained to master surgical precision and aim to cut down on medical mistakes. These models reduce errors and focus on accuracy. It is because medical AI model training covers all critical variations and edge cases within a specific domain, such as multiple imaging modalities (e.g., MRI, CT, X-ray) in healthcare or different transaction types and user behaviors in fintech applications.
Demographic Diversity: Ensuring representation of a wide range of attributes such as age groups, genders, ethnicities, and geographic regions to capture the variability in human populations.
Contextual Diversity: Adding varied environmental and situational factors so that the model learns from context, such as variations in weather conditions, ambient noise, or physical settings, enhances accuracy and precision in model output.
Reasons for Overfitting
Overfitting happens when an AI/ML model learns too much from its training data. When a model learns patterns specific to the training data rather than generalizing patterns applicable to new data, it is unable to perform well on new data. Instead of focusing on general patterns, it memorizes the details and noise in the training set.
The main reasons are:
• The training data is too small and doesn't represent all possible scenarios.
• The data includes too much irrelevant information (noise).
• The model is overly complex and learns patterns that don't generalize.
• Training goes on for too long, causing the model to overfocus on specific data.
Examples of Overfitting
Imagine a model trained to detect pedestrians in urban surroundings. If most image annotations show pedestrians on city streets, the model might struggle to recognize pedestrians in rural settings or on hiking trails, limiting its effectiveness in different scenarios.
Another example is a model predicting university graduation rates. If trained only on data from one gender or ethnicity, it may struggle to make accurate predictions for other groups. This happens because the model overfits to patterns specific to the limited training data.
The goal of machine learning is to strike a balance: learn enough to identify patterns but not so much that the model can't adapt to new situations. To combat overfitting, services by data annotation companies must prioritize creating diverse and representative datasets.
The Role of Data Annotation in Achieving Diversity
Data annotation, the method of labeling data for AI training, is the foundation for model development. Data annotation companies are responsible for curating datasets that reflect real-world distinctiveness.
Annotated data should be sourced from multiple environments, devices, or demographics to ensure a variety of scenarios. For instance, speech recognition systems should include accents, dialects, and background noises.
Annotators with domain expertise can ensure that specific nuances within a dataset are appropriately captured. For example, medical data annotation benefits from certified radiologists or pathologists to ensure compliant and precision labeling.
Integrating edge cases, rare but critical factors, helps prevent overfitting. For instance, self-driving car models should include image annotations of unusual weather conditions or rare road incidents.
Conducting frequent data audits ensures the dataset remains up-to-date and unbiased. This method reduces the risk of the model becoming outdated or skewed.
The Implications of Data Diversity in AI
By 2030, AI is expected to grow the industry by $15.7 trillion (PwC), with the largest gains occurring in the retail, finance, and healthcare sectors. An AI model can significantly benefit businesses and society by simplifying human tasks, provided it is trained effectively.
However, there are consequences of avoiding model overfitting. They are:
Bias in AI Models: Homogeneous datasets often result in biased machine learning models that fail to serve certain groups, such as underperforming facial recognition systems for certain ethnicities.
Reduced Scalability: A narrow model may work well in one region or scenario but fail when introduced to new marketing needs.
Loss of User Trust: End-users lose confidence in ML models that produce inconsistent or inaccurate results.
Increased Costs: The need for retraining and redeployment increases costs significantly.
It is beneficial to partner with data labeling and annotation companies experienced in managing large-scale and complicated datasets.
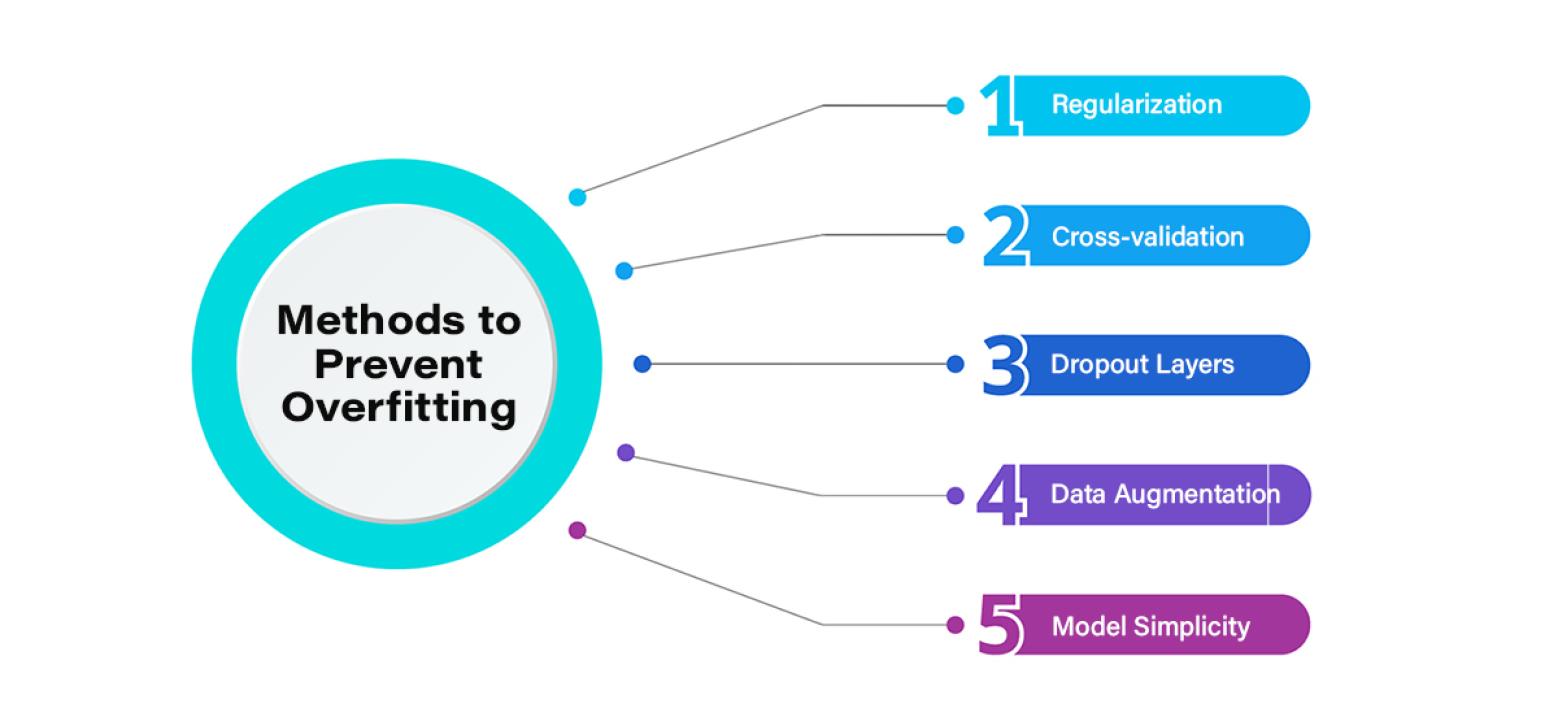
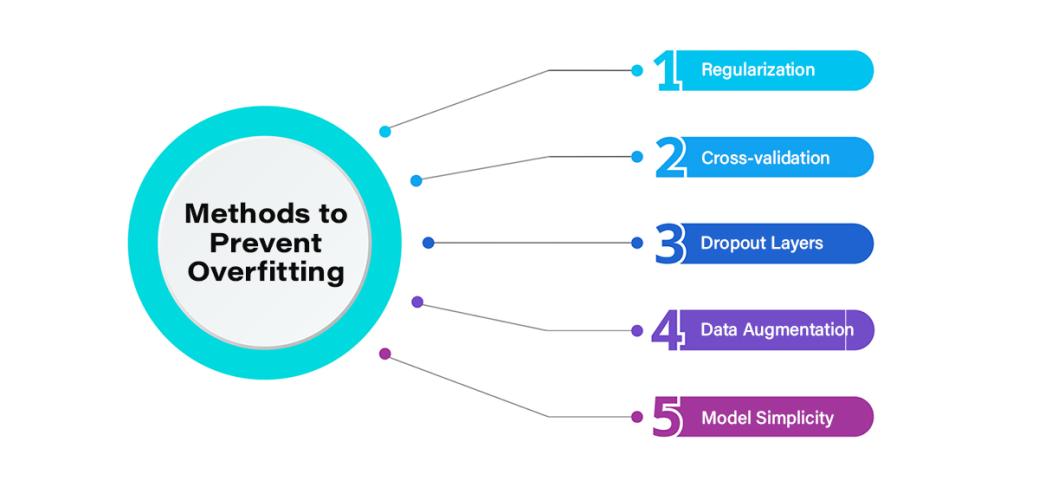
Methods to Prevent Overfitting
While data diversity is required to prevent overfitting, there are other aspects that play an equally important role. They are discussed below:
1. Regularization
Regularization is a training/optimization method to reduce model overfitting by ranking features according to their significance. It removes variables that have little bearing on predictions. For example, it uses mathematical computations to penalize qualities that have little effect.
2. Cross-validation
Cross-validation splits the dataset into multiple subsets, ensuring the model is tested against varied data during training.
3. Dropout Layers
In deep learning, dropout layers randomly deactivate neurons during training, promoting generalization.
4. Data Augmentation
For image, text, or speech data, augmentation techniques, such as rotating images, adding noise, or paraphrasing, can artificially improve data diversity.
5. Model Simplicity
Generic AI models are less prone to overfitting as they focus on general patterns instead of memorizing data.
How Annotation Companies Power AI Projects
Data annotation service providers utilize advanced annotation tools and domain experts to meet the demands of representative datasets.
Here’s how their annotation process works to make a difference:
1. Custom Annotation Pipelines
Many data labeling companies design customized workflows for AI projects to meet training data needs. For example, healthcare AI/ML models benefit from datasets annotated across multiple modalities (CT scans, MRIs, and X-rays).
2. Scalable Annotation Teams
Having large, scalable teams with professional, certified experts allows annotation companies to handle various AI projects efficiently and in a timely manner.
3. Quality Assurance
Check your annotation service provider offers regular quality checks, to ensure that annotations are accurate and uniform across all kinds of AI projects.
4. Ethical Data Practices
Adherence to ethical and legal considerations when using an AI model helps ensure seamless deployment and avoid AI biases. A compliant-labeled training data is the need of the hour to support data scientists' projects while ensuring adherence to legal regulations.
Real-World Applications of Data Diversity
1. Healthcare
AI diagnostic tools and training on diverse data points give accurate responses because it is inclusive of different populations.
2. Autonomous Vehicles
Self-driving cars must navigate varied conditions, including different lighting, terrains, and traffic laws. Diverse annotated data is critical to train models for such complexity.
3. Fintech
In fraud detection systems, data diversity ensures that AI models detect fraudulent activities in transactions across different geographies and customer behaviors.
4. Retail
Recommendation systems in the retail sector perform much better when trained on datasets that reflect diverse customer preferences and behaviors.
Conclusion
To sum up, we now know how overfitting is a big challenge in model training.
Understanding data diversity issues and knowing how to address them is essential for building reliable AI models. It requires synergy between data scientists, domain experts, and data annotation providers to curate datasets that are comprehensive, unbiased, and representative.
Leading annotation companies are dynamic in their approaches to the model training process, helping businesses achieve this critical objective while maintaining efficiency and scalability.
Let us know what is your way out to prevent model overfitting? How do you gain a competitive edge in this AI landscape!